
Jun 25
/
Luis Ehbauer
AVMs verstehen – Theorie und Praxis

Willkommen zurück im KIBI Blog – Ihrem Informationsportal für KI in der Bau- und Immobilienwirtschaft!
Am KIBI Institut haben wir bereits in unserem Überblicksbeitrag zur KI-gestützten Immobilienbewertung Grundlagen und Einsatzszenarien vorgestellt siehe:
Am KIBI Institut haben wir bereits in unserem Überblicksbeitrag zur KI-gestützten Immobilienbewertung Grundlagen und Einsatzszenarien vorgestellt siehe:
Heute wollen wir tiefer eintauchen und die Funktionsweise automatisierter Bewertungsmodelle (AVMs) auf einer soliden theoretischen Basis erläutern sowie ein Praxisprojekt aus meinem Masterstudium an der IREBS in Regensburg vorstellen, in dem diese Konzepte praktisch angewendet wurden.
KIBI-Info: Die folgenden Erläuterungen vermitteln die grundsätzlichen Prinzipien von Automated Valuation Models (AVMs). Bitte beachten Sie, dass kommerziell eingesetzte AVMs in ihrer Modellkomplexität und Datenbasis oft deutlich weitergehen als die hier beschriebenen Basis-Methoden.
Theoretische Grundlage zu AVMs
Was sind AVMs?
Automatisierte Bewertungsmodelle (AVMs) sind rechnergestützte Systeme, die Immobilienwerte mit Hilfe statistischer und Machine‐Learning-Verfahren schätzen. Sie greifen auf vielfältige Datenquellen zurück – Objektmerkmale, Vergleichswerte, sozioökonomische und Geodaten – und ermöglichen Einzel- wie Massenbewertungen
Automatisierte Bewertungsmodelle (AVMs) sind rechnergestützte Systeme, die Immobilienwerte mit Hilfe statistischer und Machine‐Learning-Verfahren schätzen. Sie greifen auf vielfältige Datenquellen zurück – Objektmerkmale, Vergleichswerte, sozioökonomische und Geodaten – und ermöglichen Einzel- wie Massenbewertungen
Zentrale Technologien und Anwendungsschritte
- Supervised Learning: Modelle (z. B. lineare Regression, Random Forests, Gradient Boosted Tree) lernen aus annotierten Datensätzen Muster, um diese auf unbekannte Daten anzuwenden und damit Zielwerte (Marktwerte) abzubilden.
- Parametrische Modelle (z. B. lineare Regression, Mixed-Effect-Modelle): Nutzen explizite Annahmen zur funktionalen Form und bieten klare Interpretierbarkeit bei geringen Datenanforderungen.
- Semi-parametrische Modelle (z. B. Generalized Additive Models, Geographically Weighted Regression): Kombinieren die Nachvollziehbarkeit parametrischer Ansätze mit flexibler Abbildung nicht-linearer Zusammenhänge.
- Nicht-parametrische Modelle (z. B. Entscheidungsbäume, Ensemble-Verfahren, neuronale Netze): Verzichten auf a-priori-Annahmen, erzielen hohe Prognosegenauigkeit und lassen sich trotz ihrer fehlenden Erklärbarkeit und "Black-Box" Problematik mittels Explainable-AI-Methoden zunehmend besser interpretieren.
- Datenaufbereitung: Bevor ein AVM trainiert wird, müssen die Eingabedaten geprüft und bereinigt werden: Ausreißer werden entfernt, fehlende Werte ergänzt und die Verteilung der Variablen durch Transformationen z. B. Logarithmieren an die Anforderungen des Modells angepasst.
- Modelltraining & -validierung: Vorgehensweise umfasst Train-Test-Split (z. B. 80 % Training, 20 % Test), k-Fold-Cross-Validation und Moving-Window-Ansatz, um Generalisierbarkeit und Robustheit zu prüfen.
Fehlermetriken im Überblick
Zur Beurteilung der Qualität von AVMs werden üblicherweise folgende Fehlermaße herangezogen: Der Mean Absolute Error (MAE) beschreibt die durchschnittliche absolute Abweichung der prognostizierten Werte von den tatsächlichen Immobilienpreisen, während der Mean Absolute Percentage Error (MAPE) die mittlere prozentuale Abweichung angibt. Ergänzend dazu gibt das adjustierte Bestimmtheitsmaß R2adj Auskunft über den Prozentsatz der Streuung, der durch das Modell erklärt wird. Je nach Anwendungsfall werden diese Metriken kombiniert, um sowohl Validität als auch Genauigkeit der Bewertungen umfassend zu beurteilen.
Praxisprojekt: AVM an Daten aus Hamburg
Aufgabenstellung
Im Rahmen einer semesterbegleitenden Leistung meines Masterstudiums am Lehrstuhl für Immobilienmanagement der IREBS – International Real Estate Business School sollte ein Minimum Variable Product eines AVM´s entwickelt und anhand eines Datensets bestehend aus Hamburger Wohnimmobilien getestet werden. Die Immobilienbewertung mit der Machine Learning Methode wurde dabei mit der Software und Programmiersprache R aufgesetzt und durchgeführt.
Umsetzungsschritte
- Datenimport und -bereinigung
Zunächst wurde das CSV-Datenset der Stadt Hamburg in R eingelesen. Unvollständige Beobachtungen (z. B. fehlerhafte „Baujahr“-Einträge oder „n.a.“-Felder in der Ausstattungsnote) wurden identifiziert und entfernt. Kategorische Variablen wie „Verwendung“, „Keller“ und „Objektunterart“ wurden konsolidiert und gleichbedeutende Kategorien zusammengeführt. Anschließend erfolgte eine einzelfallbezogene Prüfung numerischer Werte (Wohnflächen-, Marktwert- und Altersangaben), wobei Ausreißer durch Festlegung realistischer Intervalle eliminiert wurden. - Datentransformation
In dieser Phase wurden Dummy-Variablen für alle kategorialen Merkmale erzeugt und eine quadratische „age²“-Variable eingeführt, um nicht-lineare Alterseffekte abzubilden. Marktwert und Wohnfläche wurden logarithmiert, um schiefe Verteilungen zu normalisieren und die Voraussetzungen für lineare Modelle zu erfüllen. - Modellerstellung und -auswahl
Es wurden mehrere lineare Regressionsmodelle (Lin-Lin vs. Log-Log) aufgebaut und anhand des adjustierten R² miteinander verglichen. Das Log-Log-Modell zeigte die bessere Passung und bildete die Basis für ein multiples Regressionsmodell mit ausgewählten Einflussgrößen, wobei auf Multikollinearität und geeignete Referenzkategorien geachtet wurde. - Validierung und Ergebnisauswertung
Die Güte des finalen Modells wurde mittels eines Moving-Window-Ansatzes auf Trainings- und Testsets (2019/2020) überprüft sowie anhand von KPIs wie MSE, RMSE, MAE und Residuen-Standardabweichung beurteilt. Die enge Übereinstimmung von vorhergesagten und tatsächlichen Werten bestätigte die Zuverlässigkeit des Ansatzes. Abschließend wurden Potenziale zur Optimierung—etwa durch komplexere ML-Verfahren oder eine Erweiterung des Datenumfangs—diskutiert.
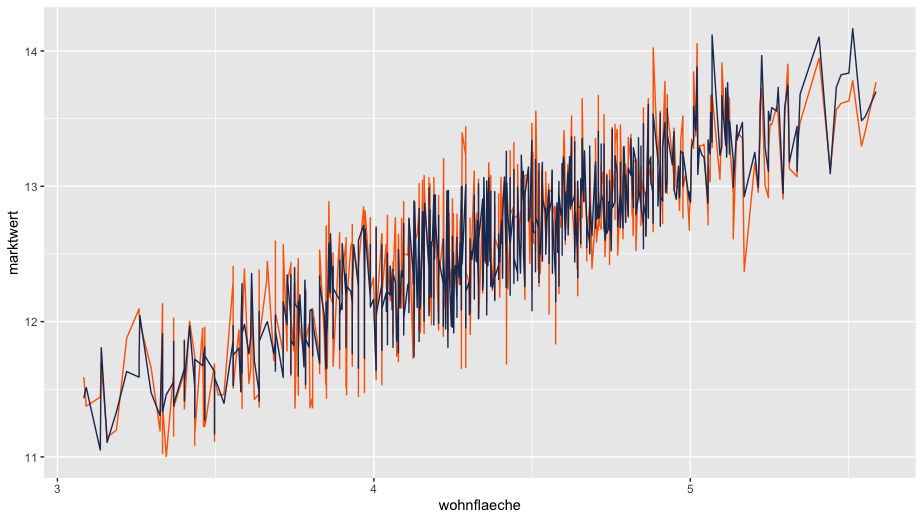
Die Grafik veranschaulicht für das Jahr 2019 den Vergleich zwischen den von unserem AVM prognostizierten Marktwerten (blaue Linie) und den realen Transaktionspreisen (orange Linie) über verschiedene Wohnflächen. Die enge Übereinstimmung der beiden Kurven spricht für eine hohe Genauigkeit des Modells.
Keine Scheu vor AVMs – das KIBI Institut unterstützt
Die Mechanismen hinter AVMs mögen auf den ersten Blick komplex wirken. Doch zahlreiche PropTech-Anbieter haben diese Methodik in benutzerfreundliche Softwarelösungen eingebettet. Und: Das KIBI Institut begleitet Sie dabei,
- theoretisch durch vertiefende Kurse und Fachpapiere,
- praktisch durch individuelle Tool-Evaluierung und Integration,
- sowie operativ bei der Entwicklung maßgeschneiderter AVM-Strukturen für Ihre Portfolio- oder Standardbewertungen.
Wir setzen selbst AVM-Lösungen für unsere Mitglieder in der Portfolioanalyse ein und helfen Ihnen, den Schritt zur digitalen, KI-gestützten Immobilienbewertung souverän zu meistern.
Weiterführende Literatur:
Copyright © 2026.
Created with
